GROUP BY는 모르는 사람이 없을 정도로 많이 애용되는 문입니다.
그렇다면, 이 GROUP BY는 서버의 수많은 내부 장비중에서 무엇을 주로 사용하는 것일까요?
GROUP BY는 GROUP BY다음에 나오는 컬럼을 기준으로 데이터를 묶어서 보여줄 때 사용합니다.
그렇다면, 데이터를 묶는다는 말의 의미는 무엇일까요?
일단 묶어내기 위해서는 어떤 방식으로 일을해서 묶어놓을 수가 있을까요?
제일 쉬는 방법은 묶어야 되는 컬럼을 기준으로 데이터를 줄을 세우는 방법입니다.
줄세워놓고 틀려지면 한개씩 모은담에 보여주면 그게 제일 편한 답이죠.
그러면 또 다른 방법은 뭐가 있을까요?
모든 데이터를 읽어 들이면서 종류가 다른것이 하나씩 나올 때 마다 체크해 두었다가 보여주는
방법도 있습니다. 이 두가지 방법에는 어떤 장.단점이 있을까요?
어차피 보여주는 결과에는 차이가 없지만 어찌 됐던 달라지는 데이터를 관리 해야 한다는 측면에서는
서로 다를 바가 없죠? 대신 나타날 수 있는 큰 차이를 알아 봅시다.
먼저, 나타나는 데이터의 순서를 생각해 봅시다.
처음 방법을 선택하면 묶여진 데이터가 줄을서서 그 값을 나타내어 주게 됩니다.
두번째 방법을 선택하면, 묶여진 데이터가 줄을 서있는 것이 아닌 먼저 나타는 종류별 데이터의
순서대로 그 값을 나타내어 주게 되겠네요.
이것이 오라클에서 데이터를 GROUP BY할떄와 MS-SQL에서 GROUP BY할때의 차이일 것입니다.
(물론 둘다 제가 소스를 본것도 아니기 때문에 더 복잡한 뭔가가 있을지도 모르겟습니다만,
상식적인 수준에서 생각한다면 이런 차이일 것입니다 ㅡ_ㅡa)
다음으로, 내부적인 처리에 대해서 알아봅시다. 처음방법을 선택하는 경우 GROUP BY해서
쌓여지는 데이터는 이미 줄을 서 있기 때문에 그 데이터를 굳이 확인해 볼 필요가 없습니다.
아래의 그림을 보시죠. 먼저, 우리가 실행하는 쿼리는 아래와 같다고 가정합니다.

EMP테이블에서 실제 일어나는 데이터만 살짝 살펴보죠.
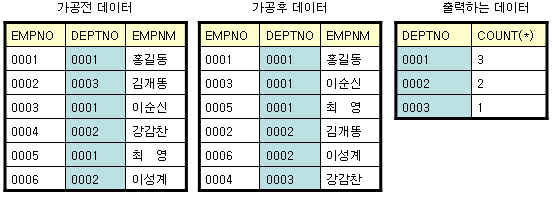
위와 같이 줄을 세워버리고 나서 데이터를 하나씩 뽑는 것은 deptno가 바뀔때만 하나씩 더해서
저장만 해주면 되기 때문에 이후 데이터를 만들어내는데 걸리는 시간이 단축됩니다.
즉,출력하는 데이터를 뽑아내는 순간에는 시간이 절약된다는 말입니다.
그러나, 이렇게 줄을 세우는 시간이 많이 걸리게 되겠지요(비교해서의 이야기입니다). 다음방법으로,
줄을 세우지 않고 뽑아내는 경우를 생각해봅시다.

이 경우는 줄을 세울 필요가 없습니다. 따라서, 줄을 세우는 작업을 하는 시간이 없어지는 대신,
출력하는 데이터를 만들어내는 과정에서 매번 지금 읽어내는 가공전 데이터가 출력하는데이터에
있나, 없나를 살펴봐야하겠지요. 따라서, 읽어내야하는 데이터도 많고 출력하는 데이터.
즉,GROUPING된 데이터도 많다면 오히려 더 느릴수도있을 것입니다.
자세한 액세스COST등은 언급하지 않겟습니다(사실 잘 모릅니다. ㅡ0-;)
자, 잠시 이야기가 옆으로 세버렸는데 이 두가지 차이에 의해서 DBMS의 GROUPING함수가 어떤 경우는
줄을 세워서 보여주고, 어떤 경우는 줄을 세우지 않고 보여준다는 것을 이해하셨을 겁니다.
위의 과정을 살펴 보셧다면 GROUP BY를 실행하면 당연히 있는지를 체크를 하기 위해서건
줄을 세우기 위해서건 CPU를 많이 사용해야만 한다는 것을 파악하셨을 것입니다.
즉 GROUP BY는 CPU를 많이 사용하는 문입니다.
이제부터는 약간의 사례를 보면서 GROUP BY를 이용하는 방법에 대해서 좀 살펴봅시다.
먼저,GROUP BY의 뒤에는 어떤 것들이 올 수 잇는지부터 살펴보죠. 제일 쉬운건 컬럼입니다.
뭐.. 이건 넘어가겠습니다. 그 다음 DECODE,CASE도 다 올수 있습니다. 아래를 보시죠.
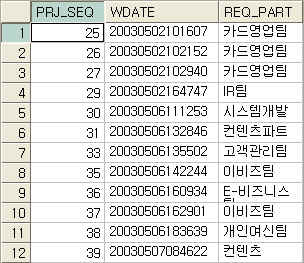
위와 같이 데이터가 등록되어 있는 테이블이 있습니다.
이 데이터를 2003년 데이터만을 가지고 어떤 부서들이 요청을 했는지 요청건수를 알아보고싶다면,
그 쿼리는 우 단순할 것입니다.
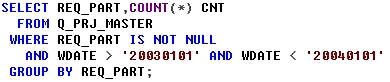
그런데 요구사항이 점점 복잡해 지게 됩니다. 각 부서별로 집계 자료를 뽑았다면,
이제 요구를 제일 많이 한 부서 부터 순서대로 등수를 만들어서 보여달라고 요청하겠지요.
이정도는 기본입니다.

"뭐 그까이꺼 이정도야~" 하면서 만들어 줬습니다. 제가 오라클을 쓰기땜시 ANALYTIC FUNCTION을
쓴것이구요, 오라클이 아니라도 충분히 만들 수 있습니다. 그건 나중에 응용에서 보기로 하고,
자 이제 새로운 요구사항이 나왔습니다.
『 1등부터 7등까지는 그냥 부서별로 몇건 했는지 보여주면 좋겟고, 8등이상의 부서는 기타로 몰아서
몇개의 부서가 몇건을 요청했는지도 함께 보여주게.』라고 하는 순간 머리에 쥐납니다. (-"-;)
일단, GROUPING하는 대상이 이제 더이상 컬럼이 아니죠.
거기다가 더하는 것도 기타부서 다 모아서 더해야합니다. 이걸 어떻게....
이제 머리가 더이상 안움직이고 정신이 없죠....
뭐.. 그렇다면 7등이내의 부서를 뽑아서 그거에 해당하지 않는 부서의 리스트를 만들어서 붙인 다음에..
어쩌고.. 어쩌고... 그럼 큰일납니다.-0-; 읽은 데이터를 최소한 3번은 읽어야 답이 나오겠네요.
그렇게 안하고 더 효율적으로 할 수 있는 방법을 찾아봅시다..
일단 1등~7등은 그냥 RANK함수가 만들어주는거 그대로 자알 쓰면 됩니다.
그럼, 8등이 넘는 부서는?... 여기서 개념이 바뀝니다. 부서별로 카운트까지는 잘했습니다.
거기에 등수도 잘 골라줬구요. 자 그럼 그게 끝일까요?... 아닙니다 아직 멀었습니다.
이번에는 이 데이터를 가지고, 등수별로 다시 GROUPING을해야 합니다.
단, 8등부터는 부서명을 기타로 바꿔놓고 해야겟죠? 두둥~ 이 쿼리를 한번 봅시다.
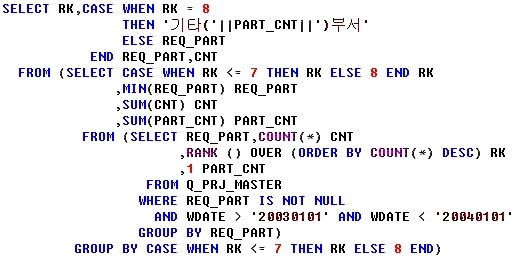
이 쿼리는 8위가 넘는 등수의 부서는 이제 부서별로 모아줍니다. 부서별 계도 당연하고,
이제 원하는 결과를 제대로 얻어냈습니다.
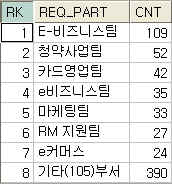
이런 형태를 이용하면 데이터를 읽어내는 횟수도 줄이고 속도 역시 향상 시킬 수 있을 겁니다.
'오라클 실무..' 카테고리의 다른 글
| DECODE와 CASE WHEN.. (1) | 2006.05.17 |
|---|---|
| 쿼리를 이용해서 달력을 만들기 (1) | 2006.05.17 |
| CASE expression (1) | 2006.05.16 |
| HINT 사용법 (1) | 2006.05.16 |
| 사용자추가하기 (1) | 2006.05.16 |